Режим разработчика
В данном режиме у вас появится возможность использовать для генерации ответа любую модель ИИ (LLM).
Например, ChatGPT, Claude Sonet, Grok, Gemini и другие.
А также, если есть желание, можно будет использовать даже любую локальную модель.
Из преимуществ данного режима:
— Вы можете указывать любое количество сообщений из истории общения для формирования контекста.
— Появляется неограниченный размер шаблона собеседования — вы можете прописать сколь угодно длинное описание.
— В адаптерах можно задавать промпты любой сложности и длины.
Всё на ваше усмотрение и вкус, полная свобода.
Теперь подробнее о том, как это работает:
Стандартный режим работы
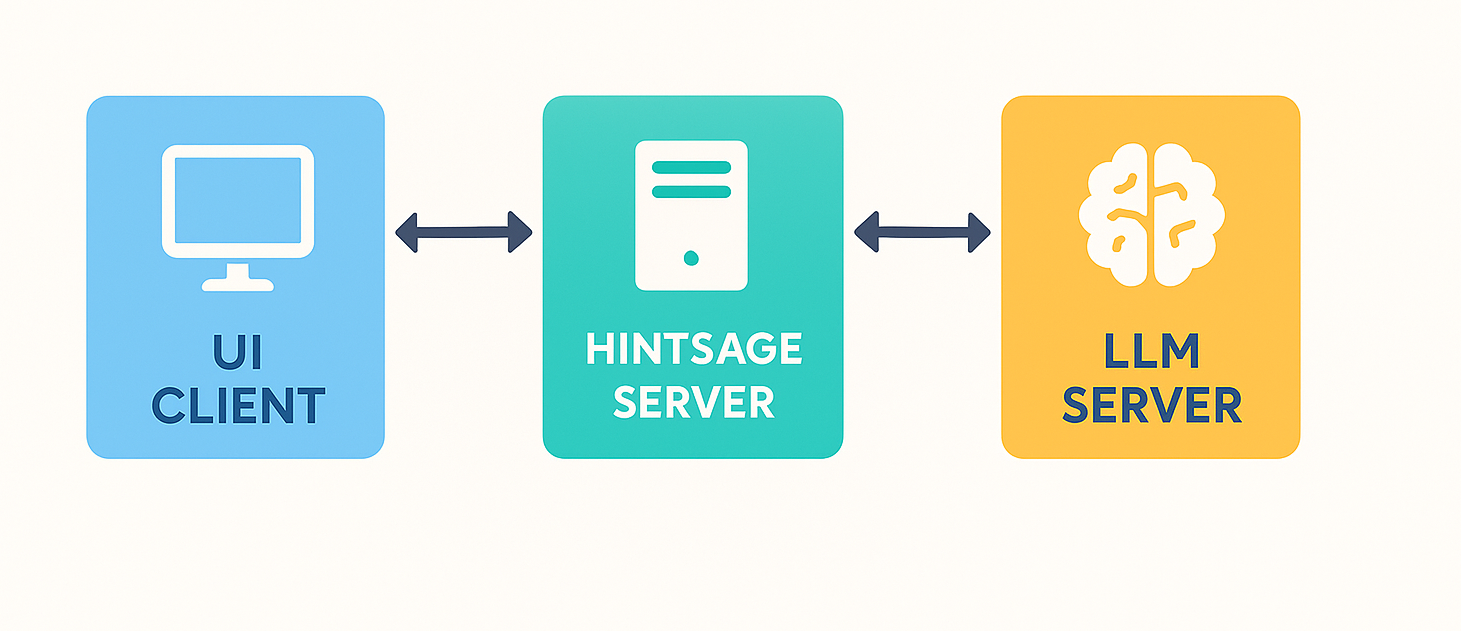
В стандартном режиме UI-клиент шлёт запрос на сервер Hintsage, который шлёт запрос к LLM модели, получает ответ и отсылает его клиенту.
В такой архитектуре вы ограничены теми моделями, которые вам может предложить сервер Hintsage.
Режим разработчика
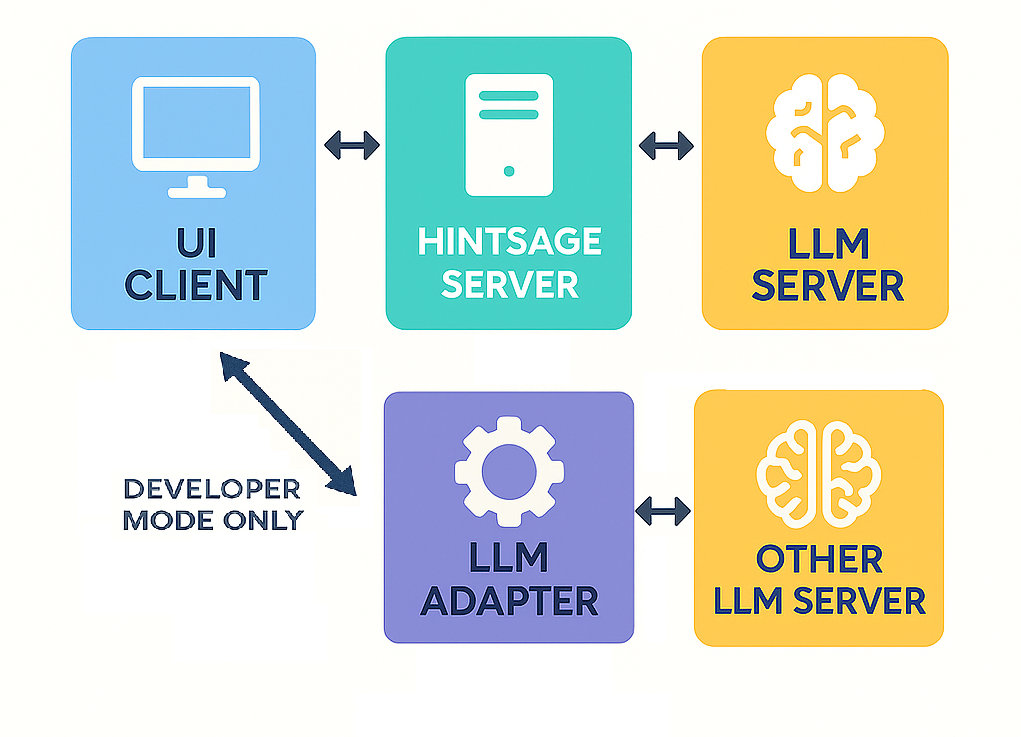
При включении режима разработчика запросы на генерацию ответа идут не на сервер Hintsage, а на локально (или удалённо) запущенный адаптер в виде сервера. Данный адаптер принимает запрос и формирует новый запрос уже к указанной вами LLM модели на основе тех данных, что он принял.
Это значит, что вы можете использовать (или написать сами) любой адаптер, который будет связываться именно с нужной вам LLM моделью.
Адаптер будет использовать ваш токен, сгенерированный на сайте сервиса, предоставляющего данную LLM модель.
- В репозитории Hintsage на GitHub выложены два примера адаптеров: для OpenAI и для OpenRouter.
Пишите собственные адаптеры и присылайте pull request с новым кодом в основной репозиторий!
Мы рады любым новым вариантам интеграции с LLM.
Включение режима разработчика
Чтобы включить режим разработчика для генерации ответов, вам нужно в файле конфигурации программы установить значение:
- На данный момент возможны два значения: OFF и LLM.
- После этого запустите сервер нужного адаптера и укажите его адрес и порт в параметре:DEVELOPER_MODE_LLM_ADAPTER_URL
- Параметр DEVELOPER_MODE_HISTORY_SIZE позволяет установить, как много сообщений из предыдущей истории общения будет передано в запросе к адаптеру в качестве контекста.
Внимательно ознакомьтесь с исходными кодами и описанием адаптеров в репозитории: https://github.com/photonius/hintsage
LLM-адаптеры
Интерфейс API
Каждый адаптер реализует два эндпоинта с одинаковыми структурами запросов и ответов.
{
"text": "Текст запроса пользователя",
"templateData": { "templateDescription": "Текст шаблона" },
"manualRequest": false,
"retryQuestion": false,
"shotThinkingModel": false,
"chatHistory": [
{ "role": "user", "content": "Текст интервьюера или пользователя" },
{ "role": "assistant", "content": "Предыдущий ответ от ИИ" }
]
}- manualRequest — Сервис Hintsage поддерживат два режима работы.
Ручной режим - это когда вы нажимаете кнопку "Получить ответ" и идет запрос на получение ответа от ИИ. В таком случае придет manualRequest = true.
Автоматический режим - это когда система постоянно определяет, был ли задан вопрос и дает ответ, только если вопрос был обнаружен. В таком режиме пользователь не нажимает кнопку получения ответа. Вместо этого система постоянно обрабатывает новые данные диалога и сама определяет, когда давать ответ.
В таком случае придет manualRequest = false. Здесь, по хорошему, вам надо определять, есть ли в новых данных вопрос, на который надо дать ответ.
В текущем коде адаптера автоматический режим не поддерживается. Но вы можете сами реализовать эту логику. Для этого вам надо определять, есть ли в пришедших данных вопрос, на который не был дан ответ. Если да - значит запросить ответ на него от ИИ, если нет - надо вернуть строку NOQ. - retryQuestion — повторный запрос на получение ответа (по правому клику мыши на сообщении).
- shotThinkingModel — использовать «думающую» модель для шотов.
- chatHistory — история сообщений (роль + текст).
Каждый фрагмент — часть ответа.
Если вопроса нет — в потоке единственное сообщение:
NOQ
- requestDto — строка, в которой сериализован JSON как в /answer/stream.
- screenshot — файл изображения.
Поток токенов ответа (аналогично /answer/stream).
Конфигурация
Все адаптеры читают параметры из config.json и/или переменных окружения:
- API_BASE — базовый URL API (например, https://api.openai.com).
- API_KEY — ключ доступа к сервису.
- ANSWER_MODEL, SHOT_MODEL, THINKING_SHOT_MODEL — имена моделей для конкретных ситуаций.
- PROMPT, SHOT_PROMPT — промпты для конкретных ситуаций.
Пример запуска
# OpenAI адаптер uvicorn openai_server:app --host 0.0.0.0 --port 8000 --no-use-colors # OpenRouter адаптер uvicorn openrouter_server:app --host 0.0.0.0 --port 8001 --no-use-colors
Рекомендации
- Все адаптеры должны:
- Принимать одинаковые DTO и возвращать поток SSE.
- Логировать ошибки и внешние вызовы.
- Новые адаптеры добавлять по аналогии: тот же интерфейс, тот же ответ.